
Adapted from a Phlexglobal Innovation Tour webinar, “Streamlining TMF Documentation through Clinical Automation,” held March 31, 2021. View the webinar – available on-demand here – to gain additional insights and details around the application of machine learning technologies to deliver improved TMF health with less effort and risk.
Regulatory agencies have increased their scrutiny of the Trial Master File in inspections, considering the TMF a key performance indicator (KPI) for GCP compliance during a study. As a result, inspectors no longer just look primarily for completeness, but expect a high degree of accuracy as well. They want documents filed in the right place consistently, and to meet the proper quality standards with minimal duplication.
Document management related to the TMF, however, is time-consuming and prone to error, requiring highly experienced professionals to perform mundane and repetitive tasks such as filing and indexing documents. In short, it represents a use case that is tailor-made for artificial intelligence.
In 2019, we started training PhlexNeuron – Phlexglobal’s machine learning framework built specifically for the pharmaceutical industry – on the Trial Master File to assess what improvements in speed and accuracy we could obtain through AI-powered automation. Following is a brief synopsis of that journey, our benchmarked results to date, and lessons learned.
AI-Powered TMF Document Management: The Key Challenges
When dealing with AI-based systems, it’s important from both a systems management and validation perspective to see the implementation as a snapshot of your current data reality. Your documents will change, so ongoing retraining and change management with your AI system are necessary to keep up with the latest data. Most critical of all: the quality of the training data drives the efficiency and accuracy of the data extraction performed by the machine-learning system.
Not too surprisingly, the things that cause problems for human reviewers also create challenges for training AI systems on TMF and document management:
- PDF documents are often scanned
- Scans can be of poor or even unreadable quality
- There is often a mix of handwritten and machine-printed text
- Many times, data provided by optical character recognition (OCR) does not accurately represent the source document
- The metadata required for timely processing of documents can be incorrect (e.g. wrong language)
- Data tagging can be incorrect or incomplete (e.g. blank fields)
So how did we overcome these challenges? We were fortunate to start with an AI framework offering sophisticated data processing capabilities already trained for document management applications in life sciences regulatory applications such as submissions. With PhlexNeuron providing a good head start, we were able to quickly train the algorithms on the proper classification of documents – for example, what zone, artifact, and sub-artifact does a document belong to.
It was also relatively straightforward to apply advanced AI technologies such as natural language processing (NLP) and support for controlled vocabularies to identify and extract the correct data – such as pulling out the last name from a physician's CV and storing it as metadata as part of the TMF. And once this metadata has been extracted and confirmed, it can serve as a foundation for streamlined integration of that data into other clinical and regulatory systems.
The second critical component in our efforts to develop efficient and accurate TMF automation was the availability of an incredibly rich set of training data: tens of millions of TMF documents which had undergone filing, indexing, and thorough quality control (QC) by Phlexglobal’s global Trial Master File experts. This deep pool of more than 150 TMF professionals also helps makes ongoing adjustments to the machine-learning algorithms, further enhancing their accuracy.
And of course, the world of artificial intelligence is not standing still. New technologies, frameworks, and algorithms appear almost daily – techniques we can leverage to the challenges mentioned previously. As you can imagine, poor-quality documents and data are not unique to the life sciences industry.
Phlexglobal AI-Assisted Indexing: Benchmarked Results to Date
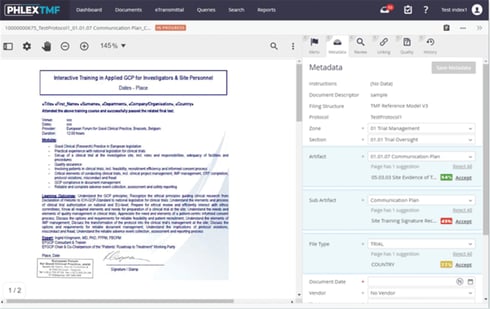 The first AI-powered TMF solution automatically classifies TMF documents and presents the confidence level of its classification for human reviewers for each artifact, sub-artifact, and file type Deployed in 2020 as part of PhlexTMF – Phlexglobal’s purpose-built eTMF SaaS solution – the AI-assisted indexing functionality has now processed more than one million real-world Trial Master File documents.
The first AI-powered TMF solution automatically classifies TMF documents and presents the confidence level of its classification for human reviewers for each artifact, sub-artifact, and file type Deployed in 2020 as part of PhlexTMF – Phlexglobal’s purpose-built eTMF SaaS solution – the AI-assisted indexing functionality has now processed more than one million real-world Trial Master File documents.
Based on our review of the TMF AI engine’s results to date, some key metrics stand out:
- Double-digit reduction in document processing effort (averaging 16% in time savings) with no impact on quality, freeing study teams to focus on other critical tasks
- Classification accuracy averaging 95%, comparable to or exceeding that of skilled TMF professionals
- Customers were able to more easily implement risk-based QC methods endorsed by regulations, further saving time and effort
And for those concerned about automation impacting their jobs, we found that our customers utilizing our AI-assisted indexing are taking advantage by shifting teams from low-value manual effort to higher-value areas – improving overall TMF quality.
Lessons Learned and the Future of AI in TMF Management
While the results we’ve seen so far are impressive, there is still room for improvement that our AI and TMF experts are focusing on. First and foremost is a lack of rich training data for certain artifacts and file types. When we look at accuracy across the Trial Master File, it becomes clear that while the overall accuracy is high, the algorithms still struggle with classifying certain documents. Not too surprisingly, these are generally the ones with the greatest amount of unstructured content, such as IRB documents.
The good news is that the more that Phlexglobal’s AI-powered algorithms are used, the more accurate they become. So if the AI hasn't made an appropriate suggestion, the indexer is going to make that selection in the old-fashioned way of selecting it via a dropdown. The algorithms are getting that immediate feedback and are continuing to learn and improve behind the scenes.
We are also looking at optical character recognition and language detection in our PhlexTMF logic, supported by PhlexNeuron, to identify quality issues with essential documents. For example, are some pages rotated? Is the scan unreadable? Instead of a reviewer spending time on these types of simple tasks, the system will notify users whether the text is readable and quality content can be extracted.
Eventually, our goal is to have a model mature enough where we can combine both the indexing and QC steps. And utilized as part of TMF management workflows – such as automatically prioritizing a larger sampling of high-risk or essential artifacts for quality control, or dynamically adjusting human sampling rates based on previous accuracy or risk – even these significant initial efficiency and quality gains will quickly be surpassed.
The bottom line? AI-powered TMF management is here today, providing significant benefits in speed and quality which will only increase over time – and helping to “take the robot out of the human.”

